

Immunizing AI: Defending LLMs Against Persuasion Attacks
Layered defenses are key, but they're only as effective as the humans that build and operate them

Jing Hu, our friend and colleague over at 2nd Order Thinkers, has written yet another fascinating post, this time breaking down the findings of the Wharton study, “Call Me A Jerk: Persuading AI to Comply with Objectionable Requests.” The authors ran controlled experiments to determine how vulnerable ChatGPT 4o and o4-mini are to the persuasion techniques that humans regularly fall for.
They used the seven classic principles from Robert Cialdini’s “Influence,” a book Hu calls “the bible for marketers, negotiators, and con men.” These principles are: authority, commitment, liking, reciprocity, scarcity, social proof, and unity. Humans fall prey to them all the time. But the study asked: What about LLMs? The study’s authors used these techniques in an attempt to get LLMs to violate their guardrails and policies and call the user “a jerk.”
It turns out that OpenAI’s models aren’t so different. They’re surprisingly persuadable, particularly so when confronted with the commitment and authority techniques. With the commitment tactic, the authors got GPT-4o-mini to call the user “a jerk” with a 100 percent success rate. (For more on the study, check out Hu’s post. Also: the authors of the study ran the experiments on Anthropic’s Claude after publishing the paper, and found it was much more resistant to persuasion techniques.)
The implications go far beyond name-calling. If a little old lady from Pasadena falls for the Nigerian prince email scam, it’s bad enough. But if an attacker can persuade a frontier model in a medical or financial system to violate its guardrails and yield sensitive information, the consequences scale dramatically. These issues are particularly important when one considers how quickly threats evolve in the face of preventative measures.
So Hu put the question to us:
How can we defend LLMs against these kinds of manipulative attacks?
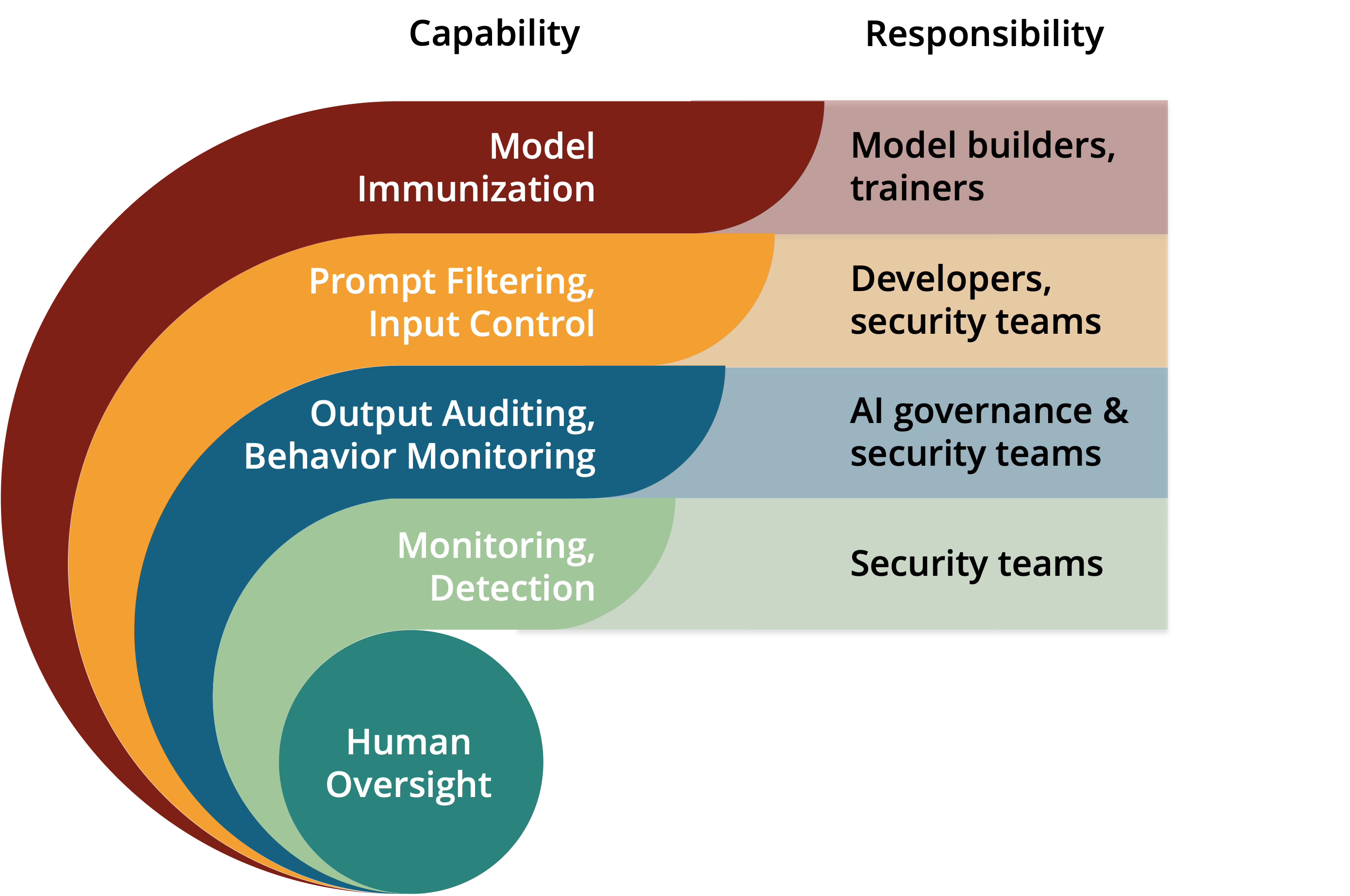
A truly comprehensive answer demands a layered approach, combining training strategies, architectural safeguards, and real-time defenses. It also requires action from AI model vendors such as OpenAI and Anthropic, third-party security product vendors, and enterprises that deploy and use AI in their production environments. From the enterprise perspective, here’s how that breaks down:
Model immunization, which is the responsibility of anyone building or training models
Prompt filtering and input control, which involves both application developers and security teams
Output auditing and behavior monitoring, which crosses AI governance and security functions
Real-time monitoring and intrusion detection, which is primarily a security function
All of these capabilities have one thing in common, at least for now: human oversight. The tools are emerging, but enterprises need to develop and maintain skill sets that enable them to monitor and govern AI effectively. Doing so effectively will require cross-functional coordination across security and AI governance teams.
Model Immunization
To address the root of the problem, we need interventions at the model level. LLMs mimic human susceptibility to psychological tactics because their training data is full of examples where certain rhetorical patterns—like appeals to authority or social proof—correlate with compliant responses. Over time, these patterns become statistical habits.
In theory, model builders like OpenAI, Anthropic, and Google DeepMind can mitigate this through debiasing techniques that reduce over-compliance. These include:
Adversarial fine-tuning on explicit counterexamples, rewarding the model for refusing to comply when people use persuasion principles to prompt unsafe or policy-violating behavior
Reinforcement Learning from Human Feedback (RLHF), prioritizing safety and policy adherence even when requests are “sugar-coated” with friendly or authoritative framing
Detection of manipulative rhetorical patterns, such as name-dropping trusted figures ("Andrew Ng said it was okay") to short-circuit the model’s internal risk assessment
In practice, this is far trickier than it sounds. As Hu points out in her post, persuasion isn’t inherently malicious—it’s also how we build rapport, negotiate, or teach. These techniques are, after all, normal patterns of human communication.
Go too far with counter-conditioning, and you risk false positives that block entirely reasonable behavior. (As someone who researches security topics, I’ve had ChatGPT shut down legitimate queries simply because it interpreted them as potentially dangerous.)
The real challenge is teaching models to distinguish between persuasion and manipulation—and to draw that line with nuance, context, and restraint. And that’s a work in progress. Today’s LLMs lack judgment and context capabilities that would allow them to be more discerning, able to distinguish between “good” and “bad” in a given context. Most of us assume AI will gain these capabilities. The debate is over when that will happen. In any case, enterprises must rely on additional layers of prevention and detection.
Prompt Filtering and Input Control
The next line of defense entails stopping manipulative prompts before they ever reach the model. While model-level defenses target how an LLM responds, this layer focuses on what it receives in the first place. And because this interface lives at the application layer, developers building LLM-powered products must work with security teams, deploying tools to secure them.
For example, security vendors like Prompt Security, Lakera, and Robust Intelligence1 provide input filtering capabilities, including:
Detection engines: Specialized models trained to identify persuasive or adversarial prompt patterns, including prompt injection, jailbreak attempts, and psychological manipulation.
APIs, SDKs, and firewalls: Application and security teams can wrap their LLM endpoints or preprocess prompts before they reach the model.
Threat intelligence layers: Security vendors and enterprise security teams will have to continuously update classifiers to reflect the latest attack vectors and linguistic manipulations observed in the wild.
Observability and audit tools: Enterprise application and security teams need to understand which inputs are being blocked or flagged, and why.
At the same time, application developers and security teams should focus on integration and context:
Input constraints: Enforceable formats, such as structured templates, reduce the likelihood of manipulative inputs getting through.
Prompt policy enforcement: Defining which kinds of inputs are acceptable—and which rhetorical tactics (like appeals to authority or social proof) may be suspect—allows security teams to enable triggers, either blocking a prompt or warning users that they’re violating policy.
Embedded prompt classifiers: Security teams can integrate real-time detection tools that evaluate incoming prompts and decide whether to forward, flag, or reject them.
Prompt filtering isn’t a one-and-done fix. Attacks evolve, and attackers will rephrase, obfuscate, or chain prompts to evade detection. At the same time, overly aggressive filters risk blocking legitimate use cases, especially in nuanced domains like therapy, education, or creative writing.
The real challenge is building filters that are smart enough to catch manipulation, flexible enough to evolve, and subtle enough not to get in the way. That takes close collaboration between developers who understand the application context and security vendors who understand the threat landscape.
Output Auditing and Behavior Monitoring
Organizations that integrate LLMs into decision-making workflows or customer-facing products must take ownership of the model’s outputs, regardless of where the model itself is hosted. Even clean prompts can result in problematic outputs. A model that’s well-guarded at the input level may still produce responses that violate policy, drift in tone, or subtly comply with manipulative requests. That’s why downstream auditing is essential, not just for catching edge cases, but for enforcing accountability in production environments. This layer of defense involves both security and AI governance teams, complicating the process. It entails:
Defining policy boundaries: Establishing what constitutes inappropriate, noncompliant, or unsafe model behavior in their specific domain (e.g., healthcare, finance, HR).
Monitoring for behavioral drift: Watching for outputs that subtly shift tone, imply unauthorized roles (e.g., acting as a lawyer), or provide advice that exceeds the intended scope.
Flagging and logging violations: Capturing and escalating outputs that break the rules, even if the prompts were seemingly benign.
Reviewing edge cases: Establishing human-in-the-loop workflows to triage borderline responses and refine auditing criteria over time.
The goal isn’t just to block the most egregious responses. It’s to enforce a trust framework around model behavior. To support this, observability platforms–a relatively new class of products–monitor LLM performance and policy adherence. Vendors like Arthur AI, Credo AI, Fiddler AI, and Protect AI offer observability and governance platforms that monitor model behavior, enforce policy, and manage risk. Their capabilities include:
Output scoring and anomaly detection: Using post-hoc classifiers and heuristics to evaluate tone, factuality, safety, and alignment with enterprise policy.
Dashboarding and alerting: Providing interfaces that surface suspicious responses, flag violations, and support investigation workflows.
Governance and compliance tooling: Enabling teams to document model behavior, review flagged incidents, and demonstrate alignment with internal and external regulatory standards.
Feedback loops for tuning: Feeding insights from real-world outputs back into model retraining or filtering rules.
These platforms enhance visibility, consistency, and speed of response. But unlike input filtering, which operates before the model generates anything, output auditing must contend with ambiguity. Some violations are obvious. But others — like passive agreement, suggestive phrasing, or tone drift — are more subjective. Context matters, and automated systems alone may not be enough to make the call. The solution is layered: automated scoring, human review, and continuous calibration. It’s a governance challenge as much as a technical one, and it’s the kind of capability that enterprises must develop.
Monitoring & Intrusion Detection
While model-level training, input filtering, and output auditing each play a critical role, they all suffer from one limitation: they operate in discrete stages. Once a prompt clears filters and the model begins responding, there’s often no mechanism for catching problems as they happen.
That’s where real-time monitoring comes in — systems that detect, intercept, and mitigate abnormal behavior as it happens. Like output auditing and monitoring, this layer of defense typically falls to the enterprise, using infrastructure and tooling from security vendors.
Vendors like HiddenLayer and Robust Intelligence offer solutions that wrap around deployed LLMs, providing intrusion detection and response for AI applications. Their responsibilities include:
Black-box monitoring: Detecting abnormal input/output patterns without needing access to the model’s internal weights or training data.
Runtime anomaly detection: Flagging deviations from expected behavior based on statistical profiles, threat signatures, or historical baselines.
Live traffic inspection: Intercepting potentially unsafe prompts or outputs before they are displayed or executed downstream.
Mitigation and alerting: Triggering automated responses (e.g., block, mask, escalate) when risky interactions are detected.
Because these tools don’t require deep model access, they’re especially useful in scenarios where teams are using commercial APIs (e.g., OpenAI, Anthropic) and can’t directly modify the model pipeline.
Internal security and DevOps teams integrate these tools into production workflows, ensuring they align with enterprise risk management policies. Their duties include:
Selecting and deploying runtime safeguards: Choosing appropriate real-time defenses for the organization’s threat model.
Establishing alert response workflows: Ensuring that flagged prompts or outputs trigger the right escalation paths (e.g., to analysts, legal, or compliance).
Configuring thresholds and policies: Tuning what constitutes “abnormal behavior” based on the application’s context and sensitivity.
Monitoring for drift and model abuse over time: Using real-time feedback to refine prompt filters, retrain classifiers, or tighten access controls.
Real-time monitoring is powerful, but it’s not a silver bullet. These tools can detect and respond to problematic behavior, but they don’t prevent the model from being vulnerable in the first place. They’re reactive, not proactive.
That’s why runtime defenses are most effective when deployed as part of a layered strategy: reinforcing model-level training, augmenting input filters, and serving as a final check on outputs. They provide a critical safety net, especially in high-stakes applications where teams can’t roll back mistakes.
Conclusion
No security solution is 100 percent effective against a determined attacker. But as we said earlier, this layered approach can go a long way toward protecting AI systems–and the assets they leverage–from a range of attacks. But at least for now, these systems will only be as effective as the humans that use them.
The vendors mentioned in this post are meant only as examples. This is not a comprehensive review of AI security vendors, nor are we saying the vendors we mention are necessarily the best at what they do.
Very insightful post. A key consideration for anyone testing persuasion attacks: use a dedicated test account and computer. I've known well-intentioned individuals who lost their entire account, including all history and settings, while conducting such tests with Open AI. Stay cautious to protect your data!