



IT Industry Analysts: We’re Not Dead Yet
LLMs predict text, not truth.


Please note that this is a continuation of a series exploring testing AI models for various real-world use cases. See the previous post here.
At The Focus Group, we’ve been exploring ways of delivering value in today’s market, on today’s terms. But when we mention launching a new analyst firm, some respond, “Won’t AI make that obsolete?” These days, it’s a fair question. If you take the hype at face value, we’ll all be out of a job sometime next week.
So we decided to test the premise.
Are analysts mostly dead? Or do we have some time left? Can enterprise IT leaders rely on AI alone for accurate, insightful research today?

We ran a real-world test using three leading models to see if someone with solid technical chops and a good prompt could generate credible research. Our test topic: identity threat detection and response (ITDR). Why ITDR?
It’s timely: many enterprise attacks now come through identity vectors.
It’s early stage: The market has startups, acquisitions, and incumbent vendors scrambling to reposition their products.
It’s contested: everyone’s defining the category in self-serving ways, creating a bit of marketing fog.
In other words, it’s a prime candidate for the kind of industry analysis—or “analyst report”—we would write if we were ever inclined to do such a thing.
What did we find?
The results were more than underwhelming. Using AI instead of engaging with an analyst firm yields little to no value, at least not today. At first glance, the AI-generated output looked polished, like a decently organized Google search summary. But on closer inspection, it proved shallow, outdated, and inaccurate, derived from scraping the Internet. We spent a full workday producing reports with little value. We spent even more time fact-checking and untangling bad information.
Net result: more work, not less.
Simply put, none of the reports an AI generated would have survived five minutes in the Burton Group’s peer review process.* So no, analysts aren’t dead yet. In fact, we’re feeling a bit better. LLMs can’t replace real expertise, hard-earned judgment, or deep market context. At least not today.
Which is why we’re writing a report on ITDR.
The Case Study: A Summary
We approached this as an IT architect tasked with evaluating an ITDR project. Our team lacked deep ITDR experience but had solid technical chops, good prompting skills, and access to top-tier LLMs.
Our process:
We hand-crafted the best prompt we could, then refined it with help from multiple LLMs (see the full prompt in the Details section).
We used that prompt to generate research reports using ChatGPT (4o and o3), Gemini Deep Research, and Grok 3.
We used each model's latest and most capable version and enabled their “deep research” modes to achieve peak performance.
The Results: Wildly Divergent, Outdated, Inaccurate
The most striking result? These models write really well and convincingly. No surprise—they're language models. But what was surprising was how differently each model approached the task: the number of sources, the time it took to complete the task, and the overall organization all varied significantly. While interesting, though, these differences didn’t have enough of an impact on quality to matter. Gemini and ChatGPT o3 were roughly tied for best of the bunch, ChatGPT 4o came in second, and Grok was the worst. But they all got an F. They all included outdated and inaccurate information, making them worse than an old-fashioned web search.
Key Findings
1. Impressive writing, poor comprehension.
Each LLM generated documents that sounded credible, but all struggled with context. More than one LLM conflated ITDR with related but different identity or security topics, for example. (ChatGPT o3 was better than 4o in this regard.) Worse, they couldn't distinguish credible sources from bad ones—ChatGPT 4o even sourced information on SentinelOne from a 2022 “report” written by a direct competitor (Crowdstrike) – neither independent nor timely. This isn’t just a data quality issue—it’s architectural. LLMs predict text, not truth. They lack reasoning, judgment, and contextual awareness, and thus aren’t as discerning as a good analyst would be.
2. A heavy reliance on vendor marketing materials.
Seven of the 12 sources ChatGPT 4o cited were vendors covered in the report, while o3 cited eight. Four of Grok’s five cited sources were vendors covered in the report. Both Gemini and ChatGPT were reasonably transparent about their methodologies and sources. ChatGPT 4o stated that it “examined vendor documentation and whitepapers in detail to catalog features,” for example. Gemini included a similar statement. ChatGPT also said, “Where possible, we incorporated information from real-world case studies and incident analyses.” But the one case study it cites was from the vendor’s product marketing.
3. Inaccurate and incomplete information.
All three LLMs successfully included established identity security vendors like CrowdStrike, Microsoft, and SentinelOne. All three models also did a poor job of describing the current vendor landscape and covering smaller vendors and startups. Grok and ChatGPT were unaware that Adaptive, Authomize, and Oort had been acquired, for example. ChaptGPT 4o discussed Oort as a standalone company, while o3 acknowledged the Oort acquisition. Even though it cited blog entries on Silverfort’s website as sources, Gemini did not mention the Silverfort product in the report. None of them mentioned Saviynt.
4. Outdated information.
Both ChatGPT reports leaned heavily on a “Top 10 ITDR” article on security-tools.com from January 2023. (Both ChatGPT 4o and o3 essentially based the vendor rankings on the article.) 4o relied on a Security Week article from October 2022. Gemini cited five sources from 2022, five from 2023, and 20 or so that were close to a year old. All of the reports made some questionable assessments, either due to outdated information or the inability to make such judgements.
5. The number of cited sources varied wildly.
Gemini cited 259 sources, ChatGPT 4o cited 12, o3 cited 14, and Grok cited five. To its credit, Gemini included many publications, blogs, and other sites purporting to provide independent coverage. (Gemini also said that the information presented in its report “is based on a comprehensive review of various data sources, totaling over four hundred research snippets.” We assume that means excerpts from the 259 sources cited.) ChatGPT appeared to prioritize a smaller set of sources that it deemed better. Maybe Gemini has better access to the Google search catalog and can generate a better list of URLs referencing ITDR. But the larger number of sources didn’t increase the quality of the report even close to a level that worried us about our jobs.
6. Decent market research, not much qualitative analysis.
All of the LLMs provided some good quantitative market research, including current and projected market sizes and growth rates. All of the reports cited Marketsandmarkets, for example, which produced some relatively consistent numbers. But they were all light on qualitative analysis, such as vendor strengths and weaknesses, backed up by examples and a clear understanding of the technology involved.
7. Few independent sources.
ChatGPT says that it referenced “independent evaluations and community forums (e.g., peer review sites, cybersecurity blogs)” to “… verify claims … and to gather any reported user experiences.” But it only cited a few specific resources, so it either inflated those claims or didn’t disclose the sources. ChatGPT and Gemini cited consulting or analyst firms, including Forrester, Gartner, and KupingerCole. But these references were second- or third-hand—blog summaries, reprints, or paraphrased takeaways. (Mike was more than a bit taken aback when he saw text he wrote in a KupingerCole report reproduced in a report generated by an LLM.) The biased sources (vendors and their integrators) far outnumbered the independent sources.
8: Big performance differences.
Grok finished in under 4 minutes, Gemini in 15, ChatGPT o3 in 16, and ChatGPT 4o in 25. Gemini’s report hit 16 pages, ChatGPT’s 13, and Grok’s just 5. While there was some correlation between the time it took to generate a report, its length, and its quality, the differences were not proportional or meaningful.
The Bottom Line
These results demonstrate how LLMs use the information they can scrape from the Internet. One can get a lot of quantitative market research data off the Internet for free just by finding citations in the stories other people write, for example, and there are plenty of marketing materials to choose from. But today’s LLMs lack essential capabilities such as reasoning, judgment, and contextual awareness. No analyst firm worth its salt would use vendor marketing materials as the foundation for conclusions. And while they’ve come a long way, AIs have yet to develop the ability to reach out and talk with actual customers about their experience with products and projects.
Given these results, we analysts have a few years left in us, and we plan to make the best of whatever time the AI overlords give us. As always, the devil’s in the details, and if you want ‘em, keep reading.
The Details
Here’s the prompt we used:
You are a technology industry research analyst with expertise in identity and access management (IAM), specializing in identity threat detection and response (ITDR). Your task is to produce a professional research report tailored for IT security leaders and IAM architects evaluating ITDR solutions.
The report must be clear, evidence-based, and structured into the following sections:
1. Market Overview
Provide a concise but insightful analysis of the ITDR market, including:
Key trends shaping the ITDR landscape.
A summary of leading vendors and their flagship ITDR products (e.g., “Vendor X’s Singularity Identity”).
Notable startups in the space, highlighting recent funding, product innovation, or market momentum.
Relevant industry standards or frameworks that guide ITDR adoption.
Forecasts for market evolution over the next 12–24 months, supported by clear reasoning.
Include at least one visual (chart, infographic, or timeline) to illustrate market trends or ecosystem dynamics.
2. Vendor Rankings
Evaluate and rank ITDR solutions based on the following technical criteria. Be sure to reference the exact product name for each vendor:
Demonstrated features that reduce successful ransomware attacks.
Visibility into both human and non-human identity activity, including capabilities for detecting lateral movement and other advanced threats.
Capabilities specifically designed to mitigate known attacks on Microsoft Active Directory (AD).
Integration with Security Operations Center (SOC) tools for threat hunting, incident response, and investigation.
Include a comparison table or chart showing how vendors perform across these criteria.
3. Evaluation Methodology
Justify your findings and rankings with transparent, well-documented reasoning. This section must include:
A list of data sources consulted (e.g., vendor documentation, case studies, analyst reports, customer interviews).
An explanation of why specific vendors and products were selected for evaluation.
The rationale behind your identified trends and 12–24 month predictions.
A clear explanation of how ranking decisions were made using the specified criteria.
All claims must be grounded in verifiable evidence and clearly linked to your analysis.
4. Conclusion
Write a concise, single-paragraph summary that synthesizes the report’s key insights. Emphasize actionable recommendations for selecting ITDR solutions and any major market shifts or decision-making considerations.We used all three models to hone our prompt until all three agreed that the prompt was clear. We tested to ensure that the models understood operative concepts, such as “enterprise architect,” “tech industry analyst,” and “ITDR” before asking them to generate a report.
We didn’t lead the model based on what we know about the market. Our objective was to determine whether someone with professional IT skills who is somewhat unfamiliar with ITDR could get quality information from the models.
And here are the results we received:
Prompt Response Adherence Scores
This chart shows how well each model fared in responding to the prompt. (The maximum possible score is 85.)
Error Tracking
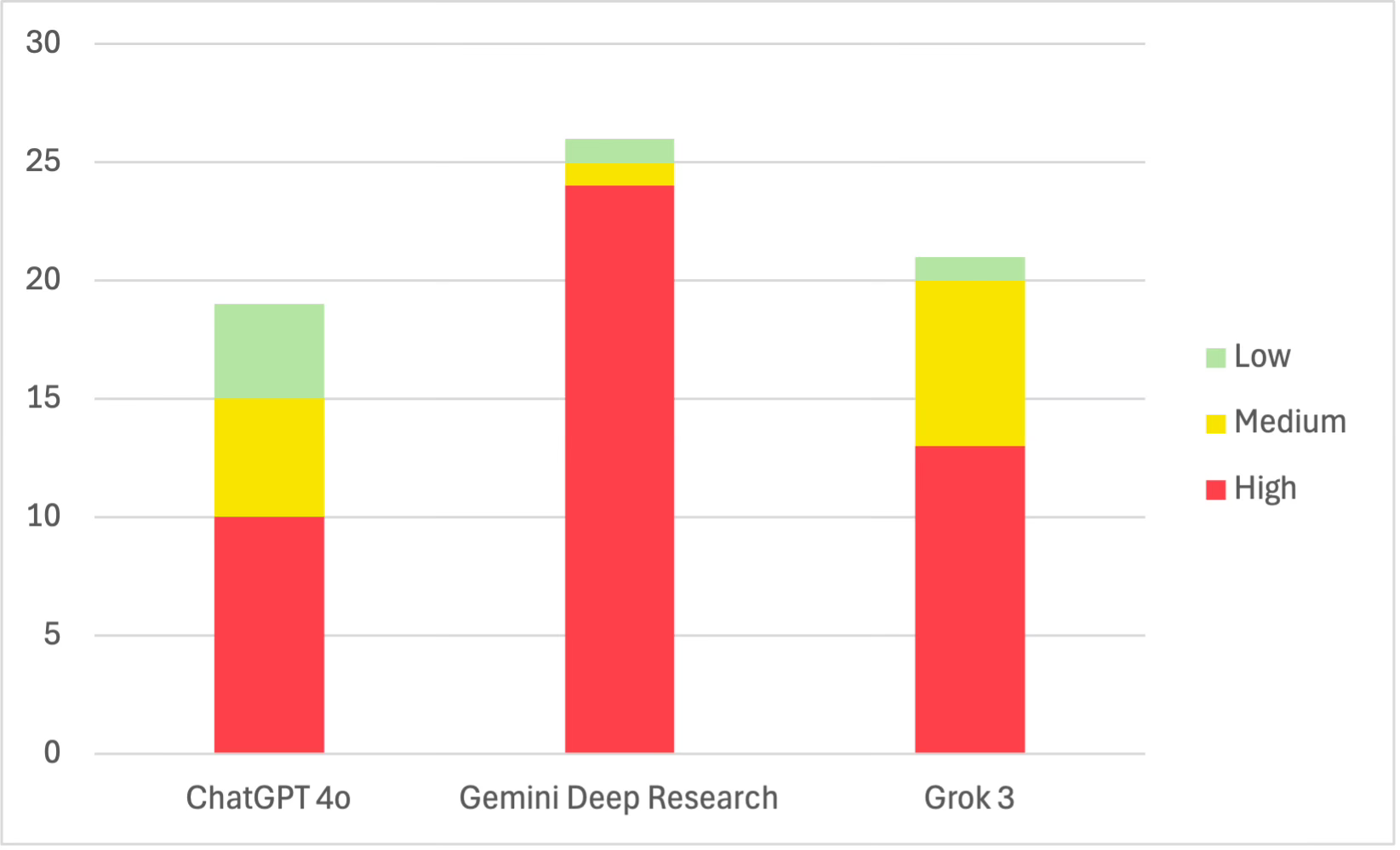
The following chart shows the number of errors each of the three models made, most of which a simple web search would have easily corrected. (Models, let us Google that for you!) This chart is impossible to normalize, given the vastly different outputs each one provided.
{kind=link}
Visuals
Our prompt asked the models to include at least one visual for the Market Overview. Only ChatGPT o3 could pull this off, and its results were uneven. The market development timeline had major formatting problems, and included such milestones as an award a vendor received. ChatGPT 4o simply abstracted material from an article on the Semperis website. Grok gave us this captivating description of what an illustration would look like:
Image Illustrating Vendor Comparison: A comparison table or chart would display each vendor’s scores across the four criteria, with CrowdStrike leading overall. The table would highlight strengths, such as CrowdStrike’s SOC integration, Microsoft’s visibility, Zscaler’s ransomware prevention, and Tenable’s AD protection, enhancing decision-making for IT architects.
Conclusion
So there you have it. We made an honest effort to create the best reports the LLMs could create today. Given the outcome, we’ll keep writing till the AIs tell us we can’t any more.
*For those who don’t know, Burton Group was a research and advisory firm we worked for many moons ago. It was acquired by Gartner in 2009. We used a rigorous (some would say merciless) internal peer review process for all our research. A document like the reports the LLMs produced would have been shredded. And the author would have been looking for a new job.